효과적인 데이터 처리 : 데이터 파이프라인 아키텍처 개념과 구성요소 및 적용사례
데이터 파이프라인 아키텍처의 중요성과 이 아키텍처가 대량의 데이터를 처리하는 조직에 어떤 장점을 가지고 있는지 다루겠습니다. 그리고 데이터 파이프라인 아키텍처의 주요 구성요소와 금융, 의료 및 마케팅과 같은 산업분야에서의 사용사례들 소개하겠습니다.

효과적인 데이터 처리 : 데이터 파이프라인 아키텍처의 개념과 구성요소 및 적용사례
데이터 파이프라인 아키텍처 소개
데이터 파이프라인 아키텍처(data pipeline architecture)는 효율적인 제어방식으로 소스에서 대상으로 이동하고 처리하는 프로세스를 말합니다. 잘설계된 데이터 파이프라인은 다양한 소스에서 대량의 데이터를 처리하여 기업의 데이터의 품질과 정확성을 보장하기 위해 조직에 필수적 옵션으로 떠오르고 있습니다.
적절하게 설계된 데이터 파이프라인을 통해 조직은 의사결정 프로세스를 개선하고, 시간 절약과 비용 절감 그리고 경쟁우위를 선점할 수 있습니다.
데이터 파이프라인 이해 : 개념과 용어
데이터 파이프라인의 주요 구성요소를 자세히 살펴보기 전에 데이터 파이프라인 아키텍처 분야에서 일반적으로 사용되는 몇가지 기본 개념과 용어를 이해하는 것이 중요합니다.
- 데이터 수집 : 원본에서 파이프라인으로 데이터를 가져오는 프로세스
- 데이터 처리 : 파이프라인을 통해 이동하는 데이터를 변환하고 조작하는 작업
- 데이터 저장소 : 처리하는 동안 데이터가 일시적 또는 영구적으로 저장되는 장소
- 데이터 변환 : 데이터 형식을 변경하거나 데이터 업데이트 등 데이터를 한 형식에서 다른 형식으로 변환하는 프로세스
- ETL : Extract, Transform, Load(추출, 변환, 로드)의 약자로, 소스에서 데이터를 추출하여 파이프라인의 필요에 맞게 변환한 후 대상으로 로드하는 프로세스
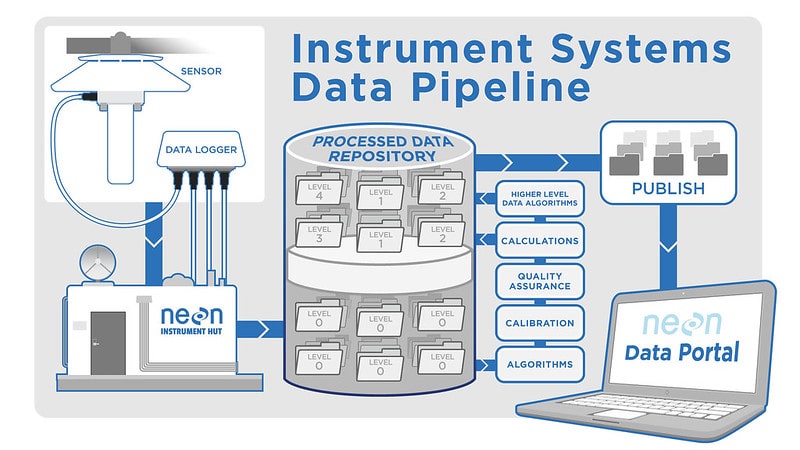
데이터 파이프라인의 주요구성요소
데이터 파이프라인은 일반적으로 일련의 처리 단계를 통해 소스에서 대상으로 데이터를 이동하기 위해 함께 작동하는 아래 네 가지 주요 구성요소로 구성됩니다.
데이터소스
데이터 원본은 원시 데이터의 출처입니다.
- 데이터베이스(예 : SQL, NoSQL)
- 스트리밍 데이터(예 : Apache Kafka)
- 파일( 예 : CSV, JSON)
- API(예 : REST, GraphQL)
예를 들어, 금융기관은 데이터 파이프라인을 사용하여 블룸버그, 로이터 및 공공시장 데이터 피드와 같은 여러 데이터 소스로부터 금융시장 데이터를 수집하고 처리할 수 있습니다.
데이터 저장소
데이터 저장소는 처리를 위해 데이터를 저장하는 장소입니다.
- 데이터 레이크(예 : Amazon S3, Microsoft Azure Date Lake)
- 데이터 웨어하우스(예 : Amazon Redshift, Google BigQuery)
- 메모리 내 데이터베이스(예 : Apache Ignite, Redis)
- 파일 시스템(예 : Hadoop HDFS)
예를들어, 의료제공자는 데이터 파이프라인을 사용하여 데이터 레이크에 환자 데이터를 저장할 수 있으며, 여기서 데이터는 통찰력을 얻기 위해서 처리되고 분석됩니다.
처리엔진
처리엔진은 데이터를 변환하고 분석하는 데 사용되는 도구입니다.
- 배치처리엔진(예 : Apache Spark, Aparche Flink)
- 스트림 처리 엔진(예 : Apache Kafka Streams, Apache Samza)
- 기계학습프레임워크(예 : TensorFlow, PyTorch)
- 스크립트 언어(예 : Python, R)
예를 들어, 마케팅 회사는 Apache Kafka Srerams와 같은 스트림 처리 엔진을 사용하여 고객 행동 데이터를 실시간으로 분석하는 데이터 파이프라인을 사용할 수있습니다.
데이터 대상
데이터 대상은 처리된 데이터가 전송되는 장소입니다.
- 데이터 베이스(예 : SQL, NoSQL)
- 데이터 웨어하우스(예 : Amazon Redshift, Google BigQuery)
- 데이터 레이크(예 : Amazon S3, Microsoft Azure Data Lake)
- 분석 및 시각화 도구(예 : Tableau, Power BI)
예를들어, 전자 상거래 회사는 처리된 데이터를 비즈니스 인텔리전스 도구로 분석하고, 시각화할 수 있는 데이터 웨어하우스로 보내는 데이터 파이프라인을 사용할 수 있습니다.
데이터 파이프란인 아키텍처의 사용사례
금융서비스
금융서비스 회사는 데이터 파이프라인을 사용하여 여러 소스에서 대량의 금융 시장 데이터를 수집하고 분석할 수 있습니다. 데이터 파이프라인은 스트리밍 데이터 수집을 위한 Apache Kafka 클러스터, 원시 데이터 저장을 위한 데이터 레이크, 배치 처리 및 데이터 변환을 위한 Apache Spark로 구성될 수 있습니다.
처리된 데이터는 추가 분석을 위해 데이터 웨어하우스로 보내지거나 모니터링을 위해 실시간 대시보드로 보내집니다.
건강관리
의료 서비스 제공자는 데이터 파이프라인을 사용하여 전자의료기록 및 웨어러블과 같은 다양한 소스로부터 환자테이터를 수집, 저장 및 분석할 수 있습니다. 데이터 파이프라인은 환자 데이터를 수집하기 위한 API, 원시데이터를 저장하기 위한 데이터 레이크, 데이터 변환을 위한 Apache Spark, 예측 분석을 위한 TensorFlow와 같은 기계학습 프레임워크로 구성될 수 있습니다.
처리된 데이터는 기록 보관을 위해 데이터 베이스로 보내거나 정밀한 관리를 위해 분석도구로 전송될 수 있습니다.
마케팅
마케팅 회사는 소셜 미디어 및 웹 분석과 같은 다양한 소스로부터 고객 행동 데이터를 수집하고 분석하기 위해 데이터 파이프라인을 사용할 수 있습니다. 데이터 파이프라인은 실시간 데이터 수집을 위해 Apache Kafka Streams와 같은 스트림 처리 엔진, 데이터 저장을 위한 인메모리 데이터베이스, 데이터 변환 및 분석을 위한 Python과 같은 스크립트 언어로 구성될 수 있습니다.
처리된 데이터는 통찰력을 얻기 위해 Tableau와 같은 시각화 도구로 전송될 수 있습니다.
다양한 소스에서 대량의 데이터를 처리하는 조직에는 잘 설계된 데이터 파이프라인 아키텍처가 필수적입니다. 데이터 파이프라인의 주요 구성요소와 함께 작동하는 방식을 이해함으로써 조직은 의사결정을 개선하고 시간을 절약하며 비용을 절감하는 효율적이고 확장 가능한 정확한 데이터 파이프라인을 구축할 수 있습니다.




댓글